Nettoyer vos données
pour des analyses fiables

Méthodos
13 février 2025
Blog
#Nettoyage
#Données
#Résultats
Après vous avoir éclairé sur la manière de traiter les réponses manquantes à un questionnaire, voyons maintenant comment faire le ménage dans vos résultats en repérant les données potentiellement à risque pour réaliser des analyses robustes et obtenir des résultats fiables.
Une fois la collecte et la saisie des données effectuées, il est en effet essentiel de procéder à une évaluation de la qualité des réponses et, si nécessaire, à un nettoyage minutieux des données. Cette étape permet d’éviter que des données incohérentes ou aberrantes ne biaisent vos résultats et vos conclusions d’étude. Dans cet article, nous attirons votre attention sur 3 types de données étant susceptibles de corrompre vos résultats.
I – Suppression des réponses incomplètes
Tout d’abord, afin de garantir la fiabilité de vos résultats, il peut être nécessaire d’éliminer les réponses partiellement remplies. Par exemple, lorsque les individus ont répondu à moins de 50 % ou 60 % des questions, ils doivent généralement être exclus de l’analyse, sauf dans le cas où les réponses incomplètes sont dues à la structure du questionnaire, c’est-à-dire aux filtres prédéfinis dans votre enquête.
De plus, il est nécessaire d’évaluer les questions elles-mêmes. En effet, si plus de la moitié des répondants n’a pas donné de réponse à une question en particulier, celle-ci peut être considérée comme non pertinente ou trop complexe. Cela peut être le cas des questions formulées sous la forme d’affirmations négatives avec lesquelles les répondants ont à donner leur degré d’accord (ou de désaccord).
Par exemple : « Mon conseiller n’est pas à l’écoute » ou « Je n’ai pas eu de retour à mes demandes ». Le traitement de la double négation est ainsi un exercice qui représente un effort cognitif particulier et n’est donc pas chose aisée. La proportion de non-réponse observée sur ce genre de question pourra donc servir d’indicateur de la compréhension de la question et devrait vous amener à ne pas tenir compte de cette variable dans votre analyse finale.

Nettoyer ses données d’enquête est important pour avoir des analyses fiables
II – Suppression des réponses « singulières »
Au-delà des réponses incomplètes, les données singulières ou aberrantes peuvent elles aussi perturber l’analyse statistique en créant des biais importants. Il est donc essentiel d’identifier et de traiter ces cas.
a) Pour les questions fermées
Pour vos questions fermées, une réponse choisie par moins de 1 % des répondants peut être considérée comme suspecte. En effet, ces réponses peuvent résulter d’erreurs de saisie, d’un manque de compréhension ou encore d’une volonté délibérée de détourner les résultats. Il conviendrait alors de procéder à une analyse plus fine du profil des répondants ayant sélectionné cette réponse.
b) Pour les réponses numériques
Pour vos questions numériques, les réponses situées au-delà ou en deçà de trois écarts types par rapport à la moyenne doivent être examinées de près. Ces valeurs extrêmes peuvent en effet indiquer des comportements anormaux ou des erreurs.
L’objectif sera alors de déterminer si ces valeurs aberrantes doivent être corrigées ou supprimées pour éviter d’affecter négativement vos résultats. En effet, les valeurs extrêmes impactent directement certains indicateurs clés tels que la moyenne (qui se retrouve alors « tirée vers le haut » ou « tirée vers le bas » selon la direction des données extrêmes) et peuvent donc changer drastiquement vos conclusions si elles sont simplement ignorées.
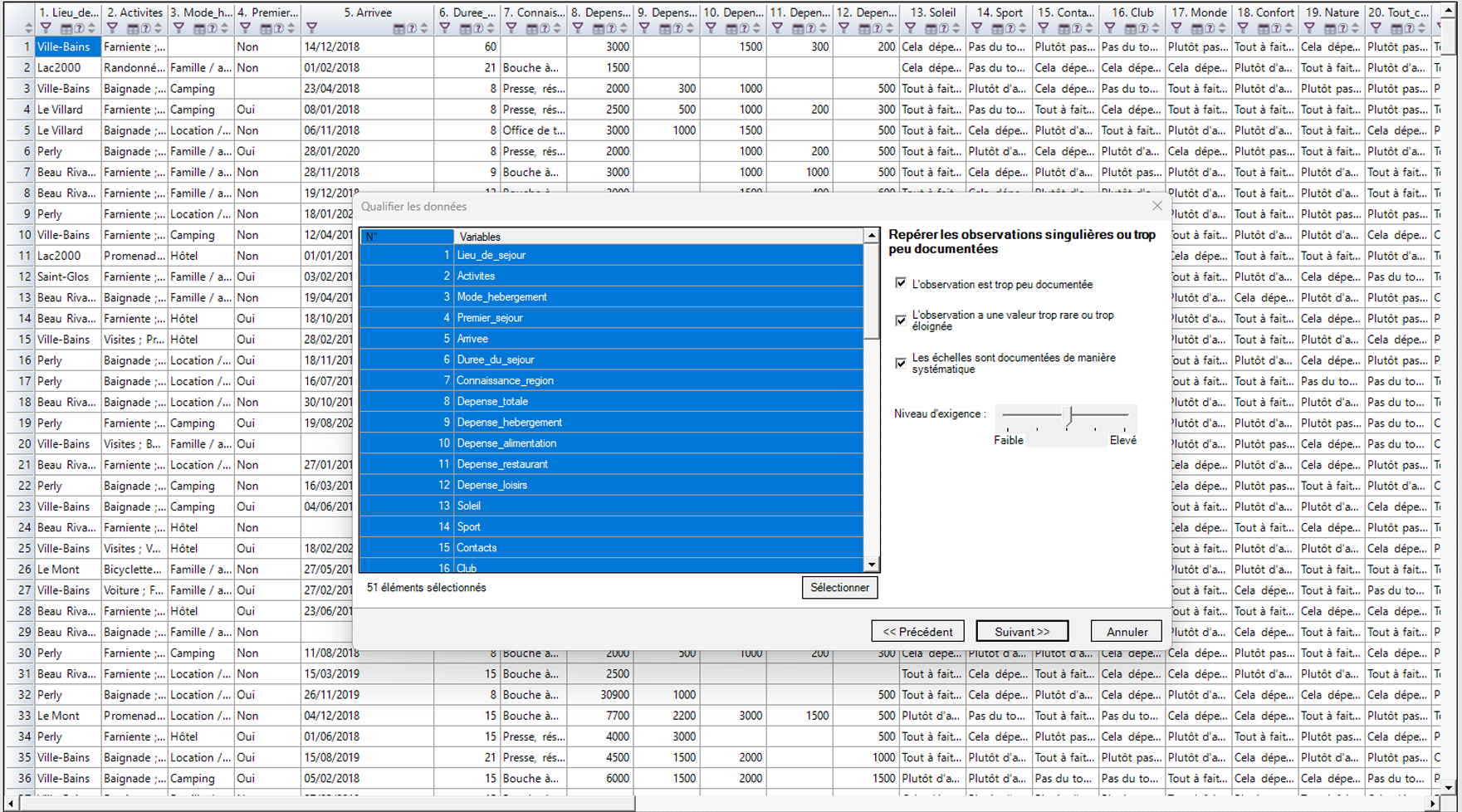
Le logiciel Sphinx iQ 3 permet d’identifier et de supprimer les réponses incohérentes de vos questionnaires
III – Suppression des réponses systématiques
Enfin, les réponses systématiques sont une autre source de biais potentiel. Elles surviennent lorsque les répondants adoptent des comportements automatiques ou malveillants durant leur participation à l’enquête.
Par exemple, nous parlons de réponse systématique lorsqu’un répondant sélectionne toujours la première option de chaque question sans réfléchir, ou encore dans le cas de questions à échelle, lorsqu’un répondant choisit toujours le même échelon, ce qui suggère un manque d’engagement dans la tâche.
Ces comportements doivent donc être identifiés et les réponses correspondantes exclues de l’analyse. Pour ce faire, des tests statistiques ou des contrôles de cohérence peuvent être utilisés pour repérer ces anomalies. Néanmoins, cela peut également se penser en amont de la collecte de données via l’introduction de questions spécifiquement destinées à repérer les réponses automatiques, aussi appelées questions-leurres. Par exemple : « Si vous lisez cette question, veuillez répondre la réponse B ». Dans ce cas simple à mettre en place, un individu dont le mode de réponse serait automatique serait identifiable de par sa « mauvaise réponse ».
Conclusion
S’intéresser à la qualité de vos données est donc une étape indispensable pour garantir la fiabilité et la validité des résultats de votre étude. Cela permet tout d’abord de prévenir les biais causés par des réponses incomplètes, singulières ou systématiques, mais cela permet également plus largement de prendre du recul par rapport à un corpus de données en s’assurant de la bonne compréhension des questions par le plus grand nombre ou encore de l’implication ou de l’engagement des répondants. C’est en adoptant des procédures rigoureuses de nettoyage que les analystes peuvent exploiter des données de qualité et fournir des conclusions précises et pertinentes. Ne pas négliger cette étape permet donc de garantir la crédibilité des études menées et de s’assurer que les décisions prises le sont sur des bases solides.
Rédigé par :
 |
Marion CHIPEAUX
Chargée d’étude chez Le Sphinx Domaines d’expertise : Psychologie, Méthodologie d’enquête par questionnaire et Traitement statistique de données quantitatives. Après plusieurs années passées dans le monde académique en tant que chercheuse en Psychologie sociale au sein de l’Université de Genève, Marion Chipeaux a rejoint l’équipe du Sphinx afin de mettre ses compétences méthodologiques et son expertise en matière de comportements humains au service des entreprises soucieuses d’optimiser et de maintenir la satisfaction de leurs clients, ainsi que le bien-être de leurs employés. |
À lire aussi

Comment optimiser le taux de réponse de vos enquêtes ?
Découvrez les 3 clés pour maximiser le taux de retour de toutes vos enquêtes, et récolter un maximum d’informations.

Le redressement : comment corriger un échantillon ?
Lorsque vous menez une enquête, il est courant que les échantillons recueillis via les réponses à votre questionnaire ne reflètent pas fidèlement la population que vous avez ciblée. Et cela peut fausser vos résultats. Il convient donc de corriger ces biais afin d’obtenir des conclusions fiables et pertinentes.
Analyse statistique : les enjeux et objectifs d’une typologie
Une typologie, ou classification, est un traitement de données qui vise à regrouper les individus étudiés en fonction de leur proximité sur un ensemble de variables. Découvrez ses enjeux et ses objectifs.