Les typologies des répondants - Partie 3 :
la classification k-means
Méthodos
16 janvier 2025
Blog
#Typologie
#K-means
#Analyse textuelle
L’analyse K-means est une méthode d’analyse statistique utilisée afin de regrouper des objets ou des individus similaires en fonction de différentes caractéristiques.
Elle est particulièrement adaptée aux grandes bases de données pour segmenter des clients ou analyser la satisfaction. Il s’agit de l’algorithme le plus célèbre en clustering.
Dans notre série de trois articles dédiés aux analyses typologiques, nous vous présentons dans cet article la classification K-means.
I – Qu’est-ce que la classification K-means ?
La classification K-means est une méthode de clustering par partition, où le nombre de clusters (k) que l’on souhaite obtenir est spécifié à l’avance. L’algorithme regroupe ensuite les observations autour de centres calculés de manière itérative.
Dans l’algorithme K-means, une itération correspond à plusieurs étapes :
- Regrouper les individus dans les clusters en fonction de leur proximité avec les centres.
- Recalculer les centres des clusters en fonction des individus attribués.
- Répéter ces deux étapes jusqu’à ce que les regroupements ne changent plus (les centres sont stables).
Contrairement à la classification hiérarchique ascendante (CHA) et à la classification hiérarchique descendante (CHD) donc, la K-means ne construit pas de structure hiérarchique mais cherche à minimiser la variance intra-cluster (c’est-à-dire minimiser la différence à l’intérieur des groupes) tout en maximisant la variance inter-clusters (c’est-à-dire maximisant la différence entre les groupes). De cette façon l’analyse optimise la position des centres des clusters pour les rendre le plus homogène possible à l’intérieur et le plus hétérogène possible entre eux.
N.B. : La position des centres des clusters est une référence indiquant la moyenne des individus appartenant à un cluster.
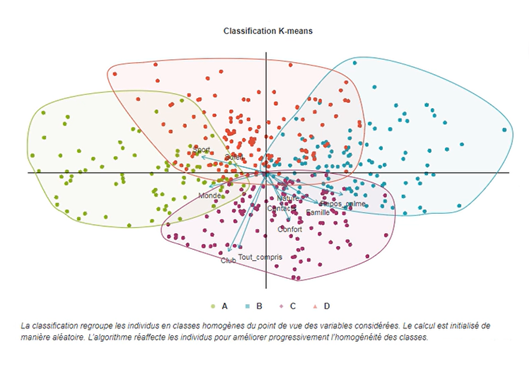
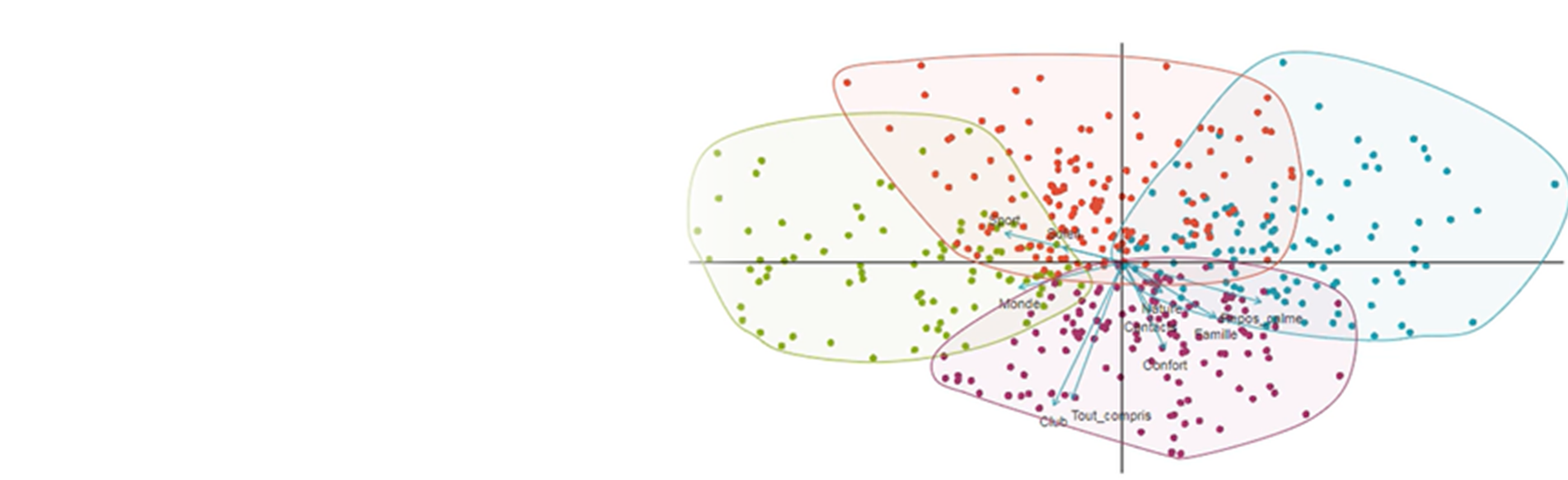
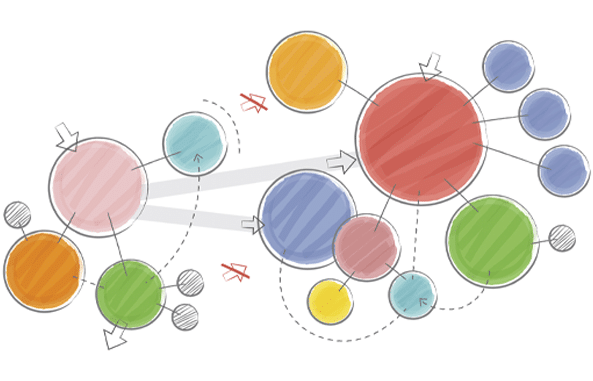
Exemple de classification K-means
II – À quoi sert la classification K-means ?
La classification K-means est particulièrement adaptée aux grands ensembles de données et aux analyses où le nombre de segments est prédéfini. Par exemple, dans une enquête de satisfaction, nous pourrions vouloir segmenter les répondants en trois groupes (satisfaits, neutres, insatisfaits).
La K-means permet ainsi de simplifier des ensembles de données complexes tout en conservant les caractéristiques essentielles.
III – Interprétation des résultats
Plusieurs éléments doivent être analysés.
Tout d’abord, la variance intra-cluster qui est un indicateur de l’homogénéité (=similarité) observée à l’intérieur des clusters. Un faible niveau de variance intra-cluster indique que les observations sont homogènes dans chaque cluster.
Ensuite, la distance entre clusters qui permet de voir à quel point les segments sont distincts. En marketing, cela aide à construire des profils bien différenciés, comme les clients engagés et les clients occasionnels.
Au-delà de ces indicateurs globaux, l’objectif reste d’analyser les caractéristiques associées à chacun des clusters, cela afin d’obtenir des insights exploitables. Pour cela, il faut essayer d’observer comment les variables clés influencent l’appartenance à un cluster ou à un autre. Exemples d’application : Découper une base de clients en fonction de leur comportement (ex. : achats, préférences, âge, etc.) sur la base de 2 clusters à « Clients fidèles » vs « Acheteurs occasionnels ».
▷ Découvrez comment réaliser une classification k-means dans le logiciel Dataviv’ by Sphinx
IV – CHA, CHD, K-means : Comment choisir ?
Ces trois classifications se distinguent principalement par leur approche et leur application.
- La Classification hiérarchique Ascendante (CHA) est ainsi idéale pour les analyses exploratoires où l’on cherche à visualiser les regroupements naturels. Cette méthode d’analyse est recommandée lorsque le nombre de clusters est inconnu ou pour des petits ensembles de données dans la mesure où elle est limitée sur le nombre d’observations traitées.
- La Classification hiérarchique Descendante (CHD) offre un contrôle sur la division des groupes et est adaptée pour des données de petite à moyenne taille. Comme pour la CHA, les performances diminuent avec de grands ensembles de données.
- La Classification K-means en revanche, est plus adaptée aux grandes bases de données avec un nombre de clusters prédéfini et pour des objectifs spécifiques comme la segmentation clients ou l’analyse de satisfaction. Il s’agit de l’algorithme le plus célèbre en clustering. Il converge en général très rapidement. Il n’est pas rare qu’il atteigne la convergence au bout de 10 itérations, même avec beaucoup de points.
Ces trois méthodes ont en commun leur capacité à créer des groupes homogènes. Cependant, CHA et CHD se distinguent par leur approche hiérarchique, offrant une flexibilité pour analyser différents niveaux de regroupement mais pouvant perdre en efficacité sur des grands ensemble de données. De son côté, la K-means, non hiérarchique, est rapide et nécessite de fixer le nombre de groupes à l’avance. Le choix dépend donc des besoins spécifiques du projet, comme la taille des données, l’importance de la hiérarchie, ou la rapidité d’exécution.
À vous de jouer 😉 !
Nos experts sont à votre disposition pour vous aider la construction d’une typologie, contactez-nous !
Rédigé par :
 |
Marion CHIPEAUX
Chargée d’études chez Le Sphinx Domaines d’expertise : Psychologie, Méthodologie d’enquête par questionnaire et Traitement statistique de données quantitatives. Après plusieurs années passées dans le monde académique en tant que chercheuse en Psychologie sociale au sein de l’Université de Genève, Marion Chipeaux a rejoint l’équipe du Sphinx afin de mettre ses compétences méthodologiques et son expertise en matière de comportements humains au service des entreprises soucieuses d’optimiser et de maintenir la satisfaction de leurs clients, ainsi que le bien-être de leurs employés. |
À lire aussi
Les typologies des répondants - Partie 1 : La classification hiérarchique ascendante (CHA)
L'analyse CHA (Classification Hiérarchique Ascendante) est une méthode d’analyse statistique utilisées afin de regrouper des objets ou des individus similaires en fonction de différentes caractéristiques.
Les typologies des répondants - Partie 2 : la classification hiérarchique descendante (CHD)
La Classification Hiérarchique Descendante (CHD) est une méthode d’analyse statistique utilisées afin de regrouper des objets ou des individus similaires en fonction de différentes caractéristiques.
Analyse statistique : les enjeux et objectifs d’une typologie
Une typologie, ou classification, est un traitement de données qui vise à regrouper les individus étudiés en fonction de leur proximité sur un ensemble de variables. Découvrez ses enjeux et ses objectifs.