Les key views
outil de Data Mining pour vos tris croisés

Logiciels
5 juin 2024
Blog
#key views
#Data Mining
#Tris croisés
Puisqu’il ne suffit pas de le dire, il est important de l’écrire : chaque entreprise collecte aujourd’hui de grands volumes de données qu’elle se doit d’analyser pour orienter ses réflexions et, in fine, ses décisions. Cette phase s’avère parfois complexe, tant les possibilités de traitements sont nombreuses, afin de rendre cette data accessible et utile à tous.
Les techniques de data mining, pour identifier rapidement les résultats significatifs
Parmi les traitements habituels figurent les croisements entre plusieurs variables. Appelés également analyses bivariées, ils peuvent être légion, surtout si la base de données dont vous disposez est conséquente. Par exemple, il est de coutume de croiser chaque variable d’identité d’une enquête (âge, fonction, genre, etc…) avec l’ensemble des autres données présentes. Dans ce cadre, l’objectif consiste à mesurer l’influence d’une ou plusieurs variables sur une autre. C’est alors le moment parfait pour que le chargé d’études, ou autre ingénieur de la data, privilégie les techniques et outils de data mining qui ont la bonne idée d’identifier rapidement les résultats les plus significatifs.
Selon Stéphane Ganassali, maître de conférences en sciences de gestion, « les techniques et les outils de data mining permettent au chargé d’études d’explorer un grand nombre de relations possibles parmi un très grand nombre de variables de son étude. L’idée centrale de cette famille de méthodes est de faciliter un accès plus rapide et plus visuel aux informations essentielles, aux relations les plus significatives, contenues dans un vaste ensemble de données. »
Le data mining, ou fouille de données en français, est ainsi un processus d’exploration et d’analyse de grandes quantités de données pour découvrir des motifs cachés, des relations, des tendances ou des informations utiles. Il utilise des techniques statistiques, de machine learning et de l’intelligence artificielle pour transformer des données brutes en informations exploitables
Les key views : des tableaux avec les résultats les plus significatifs issus d’analyses croisées
Parmi les techniques de data mining, les key views en sont une parfaite représentation. Il s’agit de tableaux de caractéristiques dont l’objectif est de « présenter dans un seul tableau les résultats les plus significatifs d’un grand ensemble d’analyses croisées ». Concrètement, nous cherchons à réduire le nombre de valeurs à présenter, en se limitant à celles qui permettent d’amener du sens. Une variable pivot est choisie, elle sera caractérisée par les modalités les plus pertinentes issues d’autres variables sélectionnées par le chargé d’études. Plus besoin donc de multiplier les tris croisés qui ont une forte tendance à surcharger des rapports parfois déjà un peu trop lourds.
Prenons l’exemple d’un baromètre social dans lequel nous souhaitons caractériser la perception du climat à l’intérieur de l’entreprise (bon, moyen ou mauvais) en fonction des caractéristiques des employés : le genre, l’ancienneté, l’âge et la fonction. Si nous choisissons d’analyser l’information au travers d’habituels tris croisés, nous recevrons une information exhaustive mais difficile à interpréter :
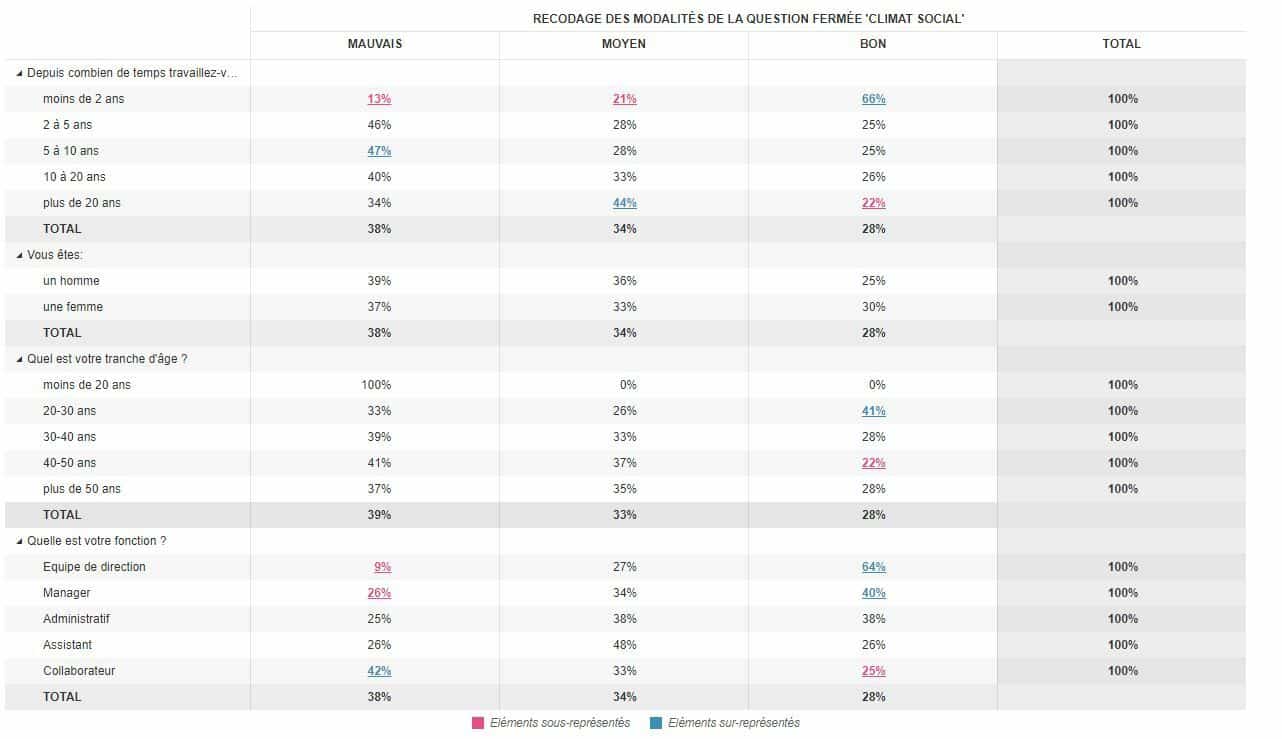
Exemple de tri croisé
Les key views vont alors combiner automatiquement la production de ces quatre tris croisés et identifier les modalités qui sont significatives entre elles, grâce à la garantie des tests statistiques. Seules les modalités surreprésentées et sous-représentées sont donc mises en avant pour clarifier au mieux l’information, et permettre une compréhension plus rapide :

Exemple de key view
Le principe de surreprésentation et de sous-représentation est associé à un test de significativité comme le Chi2 : les effectifs calculés dans chacune de vos cellules sont comparés à un effectif théorique. Si l’effectif calculé est nettement supérieur à celui qu’il devrait être et s’il n’y avait pas de relation entre les deux variables, alors nous parlons de surreprésentation. À l’inverse, si l’effectif calculé est nettement inférieur à celui qu’il devrait être théoriquement, alors nous parlons de sous-représentation.
Ainsi, le key view ci-dessus précise par exemple que, au sein de l’entreprise concernée, ce sont plutôt les collaborateurs présents depuis longtemps (5 à 10 ans), qui trouvent que le climat est mauvais. À l’inverse, les cadres (managers et équipe de direction) arrivés récemment (moins de 2 ans) estiment que le climat est bon.
L’analyse factorielle des correspondances comme représentation visuelle
Si le key view peut être représenté sous forme de tableau, comme ci-dessus, il peut l’être également sous forme de carte d’analyse des correspondances. La matrice AFC (Analyse Factorielle des Correspondances) s’intéresse justement « aux combinaisons de modalités afin d’identifier les grandes dimensions des résultats, et les modalités qui sont liées statistiquement. »
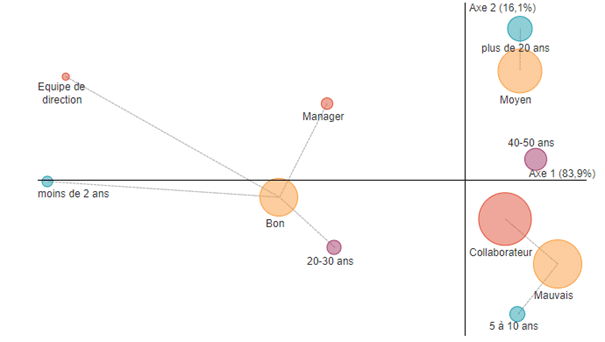
Exemple Analyse Factorielle des Correspondances (AFC)
Il s’agit-là d’une représentation visuelle qui permet de comprendre l’information principale en un clin d’œil. Nous comprenons ici que les techniques de data mining sont liées à celles de la data visualisation. En effet, tout comme le data mining cherche à faciliter l’exploration des données, la data visualisation cherche à en faciliter la lecture. Il parait alors pertinent de s’appuyer sur les forces de ces deux méthodes pour
- limiter le volume des données à explorer
- et rendre plus lisibles les éléments à observer.
Ici, dans un objectif de vulgarisation de l’information, la présentation sous forme de tableau est probablement à privilégier par rapport à l’AFC qui se veut plus technique. Toutefois, l’AFC, de par son aspect graphique, est plus susceptible de mettre en avant le storytelling de votre tableau de bord, si vous misez sur les effets de scénarisation (filtres, analyses en cascades…).
Alors, si vous souhaitez tester les key view, la solution DATAVIV’ by Sphinx, spécialisée dans l’analyse de données, la mise en forme des résultats et le partage en ligne, vous permet d’utiliser cette forme de représentation.
👉️ Essayer gratuitement DATAVIV’ by Sphinx !
Références bibliographiques : Ganassali S (2014), Enquêtes et analyses de données avec Sphinx
Rédigé par :
 |
Boris MOSCAROLA
Consultant indépendant Domaines d’expertise : les enjeux de la data, analyse de données Après 20 années passées à développer des solutions autour de la collecte et l’analyse des données quanti-quali et 15 ans à diriger la société Le Sphinx, Boris partage aujourd’hui son expérience avec les écoles et universités pour aider les futurs diplômés à appréhender les enjeux de la data pour mieux servir les entreprises. |
À lire aussi

Dataviz, parce qu’une datavisualisation vaut 1000 mots
La dataviz, est-elle un investissement judicieux dans le cadre de l’analyse des données et de la prise de décision dans un monde où le temps est précieux ?
Analyse bivariée : les 3 différents tests statistiques
L’objectif d’une analyse bivariée est de savoir s’il existe un lien entre les réponses qui sont faites à 2 questions différentes. En fonction des 2 variables à croiser, un test statistique particulier est à mettre en œuvre.
Les analyses multivariées : exemples et définitions
Lorsque vous souhaitez étudier simultanément plus de deux informations, soit plus de deux variables à la fois, il est nécessaire d'utiliser les analyses dites « multivariées ».