Blog

SphinxiDeas : un cocktail d’idées pour garder le fil et progresser
Des astuces pour optimiser votre usage des logiciels Sphinx, des méthodes, des contenus spécifiques à votre secteur d’activité, des présentations d’études et des articles de recherche… Le Sphinx vous a concocté toute une série de contenus opérationnels et instructifs dans le domaine des enquêtes et des études.

Réussir son enquête interne : les bonnes pratiques
Découvrez les 3 points essentiels pour optimiser la mesure du ressenti de vos collaborateurs dans le cadre d’une enquête de climat interne.
4 avril 2024

Les enquêtes par SMS : où comment optimiser l’expérience client
L’enquête par SMS permet d’améliorer l’expérience client grâce à son haut taux de retour, sa simplicité d’utilisation et son instantanéité. Il s’agit d’un canal de diffusion...
18 mars 2024

Comment bien formuler les questions de son enquête ?
Comment bien formuler les questions de son enquête ? Découvrez les 6 règles à respecter lorsque vous rédigez les questions de votre étude.
7 mars 2024

Les indicateurs de qualité des réponses et comment les optimiser
Quels indicateurs utiliser pour apprécier la qualité des réponses recueillies ? Quels sont les standards de la profession qui permettront de situer ses résultats par...
26 février 2024
Comment utiliser la couleur dans un dashboard ?
La mise en forme et la manière de restituer à travers le choix des images et des couleurs sont devenues capitales dans la présentation des...
16 février 2024

10 façons d‘analyser une question fermée à choix multiple ordonnés
Lors de la création de votre étude, il peut être intéressant de proposer à vos répondants une question fermée à choix multiple ordonnés. En effet,...
5 février 2024
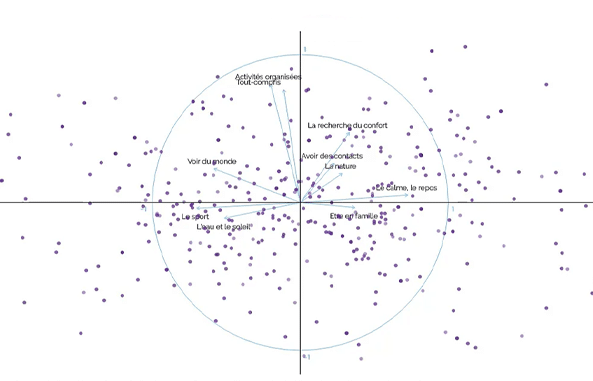
Les analyses multivariées : exemples et définitions
Lorsque vous souhaitez étudier simultanément plus de deux informations, soit plus de deux variables à la fois, il est nécessaire d'utiliser les analyses dites «...
29 janvier 2024

Comment limiter les biais dans vos enquêtes ?
Découvrez nos astuces pour réduire les biais cognitifs dans la rédaction de vos enquêtes quanti et quali, et lors de vos entretiens.
15 janvier 2024

Les différents types de biais présents dans les enquêtes
Que ce soit lors d’enquêtes quantitatives ou d’études qualitatives, collecter des données en interrogeant l’humain implique nécessairement de s’intéresser à son fonctionnement psychologique. De nombreux...
4 janvier 2024